

Data Is the Control Surface for LLMs and Agents
A technical essay on data preparation, curation, mixtures, context engineering, and verifier-backed RL

Data quality is not a scalar. Data quality is learnable structure under a compute, context, and objective budget.
Introduction: data is where intent becomes behavior
I have always been biased toward data.
Not because data work is glamorous. It is not. It is messy, repetitive, expensive, and full of judgment calls.
But in AI systems, data is where intent becomes behavior.
A model is not trained on “knowledge.” It is trained on sequences, transformations, mixtures, orderings, rubrics, rewards, traces, tool outputs, verifiers, and corrections.
An agent is not improved by “prompting” in the abstract. It is improved by deciding what information belongs in context, what should be retrieved, what should be compressed, what should be isolated, what should be verified, and what should be converted into future training or evaluation data.
The old pipeline was too small:
collect data → clean data → train model
The modern pipeline is closer to:
source → extract → clean → deduplicate → filter → transform → mix → train → evaluate → deploy → trace → verify → compile → replay
That is the data flywheel behind modern LLMs and agents.
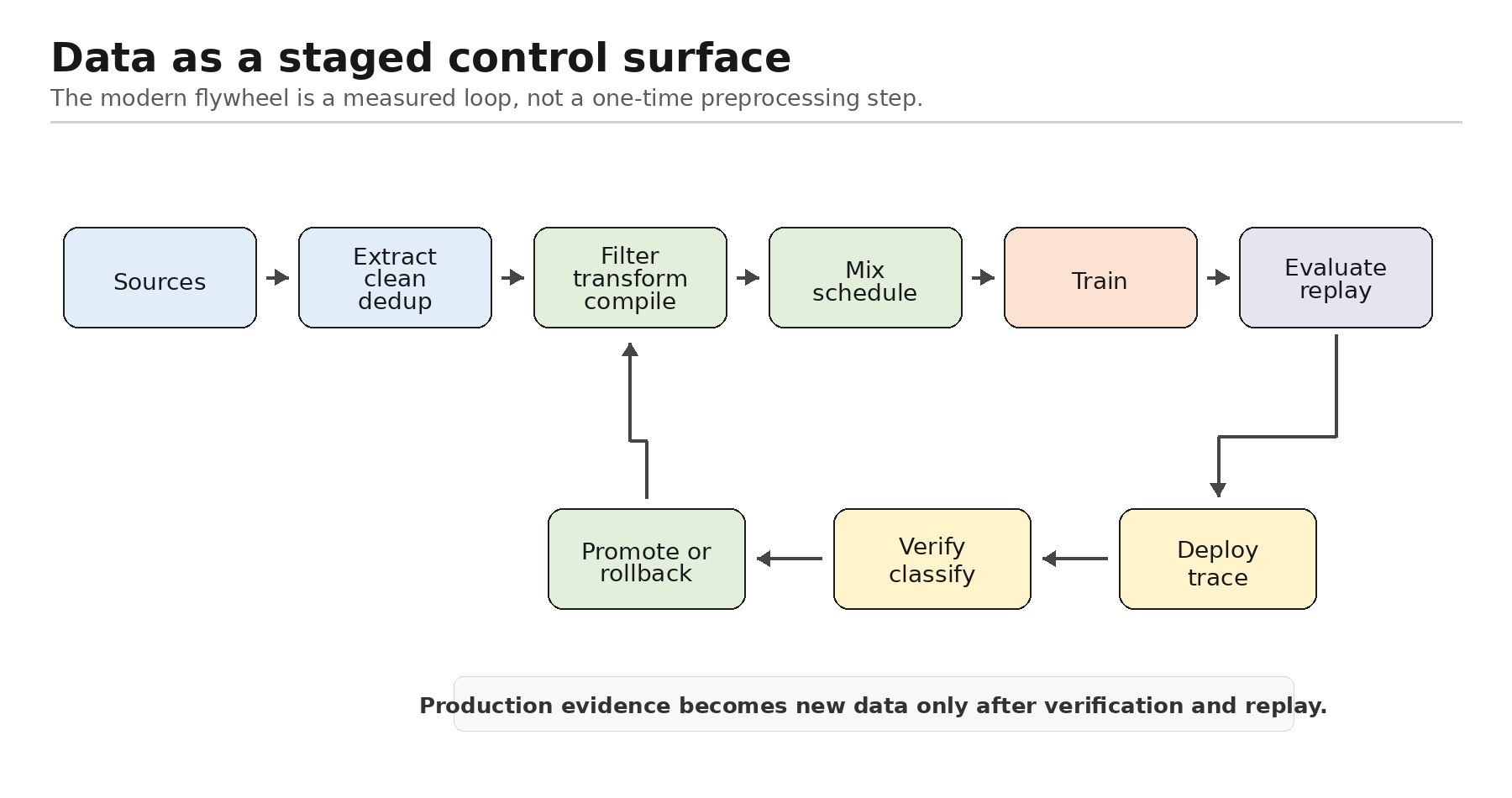
Figure 1. Data as a staged control surface across training, evaluation, deployment, verification, and replay.
The important shift is this: data quality is not a scalar. It is learnable structure under a compute, context, and objective budget.
1. Epiplexity gives us the right language
The best recent framing I have seen is epiplexity.
Classical information theory gives us a problem. It says deterministic transformations should not create new information. It says information should not depend on data order. It treats likelihood modeling largely as distribution matching.
Modern LLM practice disagrees.
Synthetic data can help.
Curriculum order matters.
Reformatting a document into instructions can improve downstream behavior.
A verifier can turn a raw rollout into a stronger learning signal.
A long context can be useless noise or a high-value playbook.
Epiplexity formalizes this gap by focusing on what a computationally bounded observer can learn from data. The paper introduces epiplexity to capture structured, learnable content for bounded learners, and explicitly addresses why deterministic transformations, ordering, and likelihood modeling can matter in ways classical Shannon or Kolmogorov framings do not capture. [1]
That is the core thesis of this post: data preparation is not janitorial work. It is the engineering of learnable structure.
The question is not “how many tokens do we have?” The better question is:
What useful structure does this data expose to this model,
at this stage,
under this objective,
with this amount of compute, context, and verification?
That is true for pretraining, post-training, context engineering, reinforcement learning, and production agents.
2. Cleaning is not just removing bad text
Cleaning is often treated as a low-status preprocessing step. That is a mistake.
For web-scale training, cleaning is one of the largest capability levers. It determines what the model repeatedly sees, what gets amplified, what gets memorized, and whether the model learns coherent human language or boilerplate, menus, spam, broken markup, affiliate pages, keyword lists, and duplicated templates.
The best public example is FineWeb. Hugging Face built FineWeb as a 15T-token dataset from 96 Common Crawl snapshots, and the paper is valuable because it documents the cleaning pipeline and ablates the choices instead of presenting them as folklore. The final pipeline extracts from WARC rather than WET, applies base filtering, performs individual per-crawl MinHash deduplication, applies selected C4-style filters, adds custom heuristic filters, and anonymizes email and public IP addresses. [2]
The details matter. FineWeb found that WET extraction retained too much boilerplate and menu text. The team instead extracted text from WARC files using trafilatura, and the WARC/trafilatura ablation produced a better model than WET extraction. The base filtering stage then used URL blocklists for adult content, fastText language identification, and MassiveText-style quality and repetition filters, producing roughly 36T tokens after base filtering. [2]
Deduplication was more subtle. FineWeb used fuzzy MinHash deduplication with document 5-grams, 112 hash functions, 14 buckets of 8 hashes, and a target of at least 75% similarity. But global deduplication across all 96 snapshots did not work as expected: it reduced the corpus to 4T tokens and gave little improvement. Worse, for an older crawl, the 10% of data retained by global deduplication was visually lower quality than the 90% removed. The better choice was independent per-snapshot MinHash deduplication, which produced 20T tokens and matched RefinedWeb performance in the ablation. [2]
Deduplication is not automatically good. Deduplication granularity changes the data distribution.
If you deduplicate too aggressively across time, you may accidentally retain the wrong tail. You may remove useful recurring explanations while keeping strange, low-quality pages that only appear once. The goal is not to maximize deletion. The goal is to remove harmful repetition while preserving useful coverage.
FineWeb also shows how heuristic filtering should be done. The team tested C4-style filters and found that terminal punctuation gave the largest individual HellaSwag boost, but removed about 30% of tokens. They chose all C4 filters except terminal punctuation because the latter deleted too much. Then they built custom filters by collecting more than 50 document statistics, comparing high- and low-quality distributions, selecting candidate thresholds, and validating them with 28B-token ablation runs. The final three custom filters removed about 22% of tokens and improved aggregate benchmark score by about 1% in the ablations. [2]
That is how data cleaning should work:
inspect → hypothesize → filter → train proxy models → evaluate → keep only filters that improve behavior
FineWeb-Edu adds another useful datapoint. It filtered FineWeb into a 1.3T-token educational subset using a classifier trained from LLM annotations. The classifier achieved 82% F1 at the selected threshold; applying it over FineWeb required 6,000 H100 GPU hours. In a 1.82B model trained on 350B tokens, FineWeb-Edu increased MMLU from 33% to 37% and ARC from 46% to 57%, while matching Matrix’s MMLU performance with almost 10x fewer tokens. [2]
That is strong evidence for classifier-based filtering when it is measured. But it also comes with a warning. Apple’s “Data-Quality Illusion” work argues that classifier-based quality filtering can improve downstream task performance while not necessarily improving language modeling on the high-quality target set. The authors challenge the assumption that classifier score captures a universal notion of quality. [3]
The right conclusion is not “classifiers are bad.” The right conclusion is that quality classifiers are instruments, not truth. A quality filter must be attached to a target behavior, benchmark suite, training stage, and ablation record. Otherwise it becomes a magic number.
3. The cleaning stack should be empirical
A modern LLM data cleaning stack should usually include:
source validation
HTML / PDF / code extraction
boilerplate removal
language identification
document normalization
PII handling
policy filtering
exact deduplication
fuzzy deduplication
near-duplicate cluster analysis
repetition filters
low-information filters
classifier-based quality filters
contamination checks
source and license metadata
benchmark-backed ablations
The important part is not the checklist. The important part is the measurement discipline.
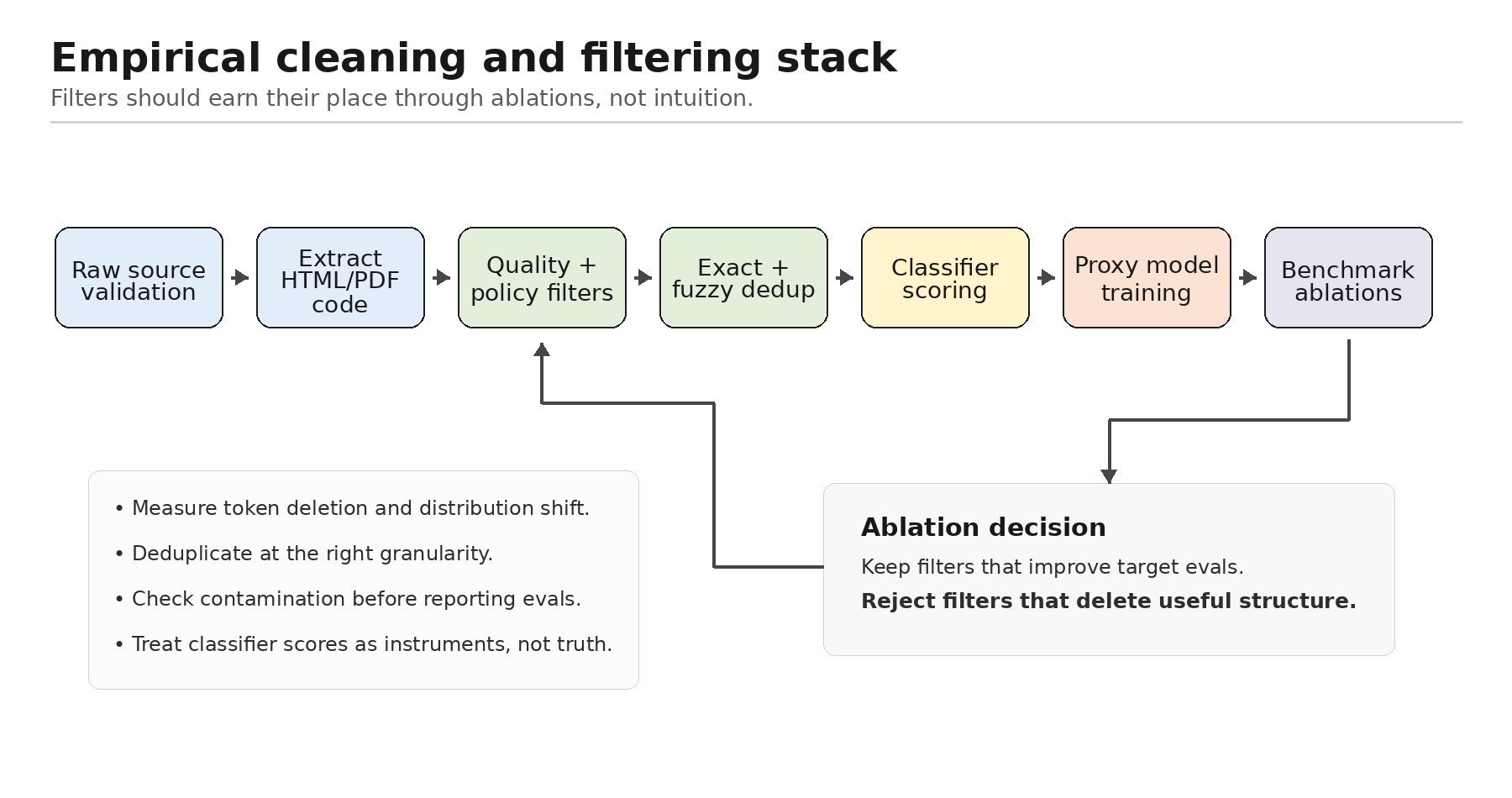
Figure 2. A practical cleaning and filtering stack with an ablation loop.
FineWeb’s ablation protocol is the right model. The team trained data-ablation models that were identical except for the data, used equal token budgets, ran multiple seeds, and evaluated on benchmarks selected for stable signal at small scale. Their ablations used 1.82B-parameter models, 28B-token filtering runs, 350B-token dedup and cumulative-filtering runs, more than 70 trained models, and roughly 80,000 H100 GPU hours. [2]
That is what data-driven data curation means. Cleaning choices should not be made by intuition alone. They should be promoted only if they improve the relevant evaluation suite.
4. Data mixtures are learned, not guessed
The next mistake is treating data mixture as a fixed human recipe. It is not. Data mixture is a hyperparameter schedule.
Different training stages need different data distributions:
early pretraining → broad coverage and diversity
late pretraining → higher-quality and capability-dense data
reasoning annealing → math, code, STEM, synthetic reasoning
long-context training → long coherent documents and long-context QA
SFT → instruction, reasoning, tools, chat, safety
preference / DPO → ranked outputs and rejected alternatives
RL → verifier-backed tasks and environments
agent training → tool trajectories, state transitions, rubrics, rollouts
NVIDIA’s Nemotron Nano 2 is a good recent example. Its pretraining mixture has thirteen categories, including quality-bucketed crawl data, synthetic high-quality crawl, math, Wikipedia, code, academic data, multilingual data, and synthetic SFT-style data. NVIDIA says it weights higher-quality sources more heavily and uses a three-phase curriculum: Phase 1 emphasizes diversity, Phase 2 shifts toward higher-quality data at the 60% training point, and Phase 3 shifts again at the 90% point. [4]
NVIDIA also discloses ablations that show how these choices are made. For multilingual data, they continued a 1B checkpoint for another 100B tokens with 50% multilingual data and 50% default pretraining data, then evaluated on Global-MMLU. Curated Common Crawl averaged 37.0, FineWeb-2 averaged 35.1, DiverseQA-wiki averaged 42.1, and DiverseQA-crawl averaged 47.0. That result led them to upweight DiverseQA-crawl in the multilingual mixture. [4]
That is the pattern we want. Not “we think multilingual web is good.” Instead: compare multilingual source families under controlled continuation, measure Global-MMLU, and change the mixture.
The same report shows that adding only 5% fundamental-reasoning SFT-style data into a 100B-token continuation improved Nemotron-H 8B’s MMLU-Pro from 44.24 to 56.36, with average math increasing by about two points and no decrease in average commonsense or code benchmarks. [4]
Qwen3 describes a complementary methodology. It trained on 36T tokens across 119 languages, including coding, STEM, reasoning, books, multilingual data, and synthetic data. It used Qwen2.5-VL to extract text from PDF-like documents, Qwen2.5 to refine that text, and Qwen2.5/Qwen2.5-Math/Qwen2.5-Coder to synthesize trillions of tokens in formats such as textbooks, QA, instructions, and code snippets. Qwen also annotated more than 30T tokens for educational value, domain, safety, and related labels, then optimized the mixture at the instance level through proxy-model ablations rather than only at source or domain level. [5]
Qwen3’s stage schedule is explicit: more than 30T tokens of general pretraining at 4K context, then about 5T higher-quality tokens with increased STEM, coding, reasoning, and synthetic data, then hundreds of billions of long-context tokens, where 75% of texts were 16K–32K and 25% were 4K–16K. [5]
So the modern methodology looks like this:
label data finely
bucket by source and quality
run proxy-model ablations
evaluate downstream capability deltas
schedule mixtures by stage
anneal toward capability-dense data
validate against regression suites
RegMix formalizes part of this. It treats mixture selection as a regression problem: train many small proxy models on different mixtures, fit a regression model to predict performance, then train the larger model on the predicted best mixture. In its experiments, RegMix trained 512 one-million-parameter models for 1B tokens, used the regression model to choose a mixture, and trained a 1B model for 25B tokens that performed best among 64 candidate mixtures. It also outperformed human selection up to 7B models trained on 100B tokens and matched or exceeded DoReMi with about 10% of the compute. [6]
The practical point is blunt: if you are not measuring mixture effects, you are guessing.
And loss is not enough. Nemotron-H reported downstream accuracy jumps after mixture changes and noted cases where validation loss was not a reliable proxy for downstream task performance. FineWeb selected filters using benchmark deltas, not just perplexity. DataComp-LM makes this broader: it provides a 240T-token Common Crawl corpus, training recipes, and 53 downstream evaluations so teams can test deduplication, filtering, and data mixing. Its baseline trained a 7B model on 2.6T tokens to 64% 5-shot MMLU, a 6.6-point MMLU gain over MAP-Neo with 40% less compute. [7]

Figure 3. Stage-wise mixture design as an experimental loop.
5. Synthetic data is a compiler, not a shortcut
Synthetic data has a bad reputation when it means low-diversity model slop. But the best synthetic data work is not “ask a model to make more examples.” It is compilation.
A raw document is not a dataset. A book is not a dataset. A manual is not a dataset. A GitHub repository is not a dataset. A support transcript is not a dataset. A tool trace is not a dataset. They are source material.
The data engineering task is to compile source material into useful training, evaluation, retrieval, reward, and context artifacts.
Instruction Pre-Training augments raw corpora with instruction-response pairs generated by an instruction synthesizer. The paper synthesized 200M instruction-response pairs across 40+ task categories and showed that instruction-augmented pretraining improved base models and made them benefit more from later instruction tuning. [17]
MAmmoTH2 recalls relevant web documents, extracts instruction-response pairs, and refines them using open-source LLMs. The project harvested 10M instruction examples from the pretraining web corpus; MAmmoTH2-7B Mistral improved from 11% to 34% on MATH and 36% to 67% on GSM8K without in-domain training data. [18]
Web Reconstruction treats each web document as either an instruction or a response and reconstructs the missing side. Its WebR datasets outperformed prior instruction-tuning baselines by up to 16.65% across four instruction-following benchmarks. [19]
Qwen3’s use of synthetic textbooks, QA, instructions, and code snippets is one example. NVIDIA’s Nemotron Nano 2 uses synthetic high-quality crawl, synthetic SFT-style data, long-document QA, and translated DiverseQA. For long-context extension, NVIDIA used academic documents longer than 32K tokens, split them into 1,024-token chunks, selected 10% of chunks for Qwen2.5-72B-Instruct to generate QA pairs, concatenated those QA pairs, and appended them to the original document. A 20% allocation of this long-context document-QA data improved RULER-128K in ablations. [4]
This is the right abstraction:
source corpus → compiled training, evaluation, retrieval, reward, and context artifacts
A book can become:
chapters
sections
claims
definitions
examples
procedures
tables
equations
edge cases
contradictions
factual QA
procedural QA
retrieval tasks
citation tasks
summaries
critiques
tool-use tasks
rubrics
unit tests
replay episodes
The invariant is provenance. Every generated artifact should point back to source spans, tool outputs, environment states, or verifier results. Without provenance, synthetic data becomes impossible to debug.
A generated QA pair is not good because it looks good. It is good if it teaches a capability, survives verification, preserves provenance, improves evals, and does not regress adjacent behavior.

Figure 4. The document-to-dataset compiler.
6. RL steering is also data engineering
Reinforcement learning is usually described as optimization. For LLMs and agents, that is incomplete. RL is a data pipeline.
The prompt distribution is data.
The rollout is data.
The environment is data.
The tool result is data.
The verifier is data.
The judge rubric is data.
The reward vector is data.
The failed trajectory is data.
The replay set is data.
DeepSeek-R1-Zero is the clean example. It used rule-based rewards for math and code: boxed-answer verification for math, compiler/test feedback for code, and a format reward for <think> tags. DeepSeek explicitly avoided neural outcome or process reward models in that stage because of reward hacking risk and retraining complexity. AIME 2024 pass@1 increased from 15.6% to 71.0%, and majority voting reached 86.7%. [8]
This is the key engineering point: if the environment can verify the work, prefer verification over taste.
For math, code, structured extraction, database queries, tool-use workflows, and many agent tasks, the best reward is often not a learned preference model. It is a test, execution result, schema check, constraint checker, exact match, or environment transition.
DeepSeek’s later R1 pipeline added cold-start long-CoT data, reasoning-oriented RL, rejection sampling, roughly 600K reasoning samples, and final training that included broader non-reasoning data. The final DeepSeek-R1 report shows strong benchmark results such as 79.8 AIME 2024, 97.3 MATH-500, 65.9 LiveCodeBench, and 49.2 SWE Verified. [8]
Qwen3 shows that RL data does not always need to be huge if the verifier is strong. Its reasoning RL stage used 3,995 query-verifier pairs, selected to be unused in cold start, learnable, challenging, and broad. Qwen3-235B-A22B improved on AIME’24 from 70.1 to 85.1 over 170 RL steps. [5]
Kimi K2 shows the agentic version. Moonshot built a large-scale tool-use synthesis pipeline with three stages: tool spec generation, agent/task generation, and trajectory generation. It fetched 3,000+ real MCP tools from GitHub and generated more than 20,000 synthetic tools; tasks were paired with rubrics specifying success criteria, expected tool-use patterns, and evaluation checkpoints. The simulator maintained state, returned realistic tool feedback, introduced edge cases, and retained only trajectories that passed LLM-judge rubric evaluation. For coding and software engineering, Kimi complemented simulation with real execution sandboxes and test-suite pass rates. [9]
NVIDIA Nemotron 3 Super shows the same pattern in an open training pipeline. It reports 25T pretraining tokens, a 7M-sample SFT stage, and a three-stage RL pipeline: multi-environment RLVR across 21 environments and 37 datasets, SWE-RL with OpenHands and Apptainer containers, and RLHF with a principle-following generative reward model. [10]
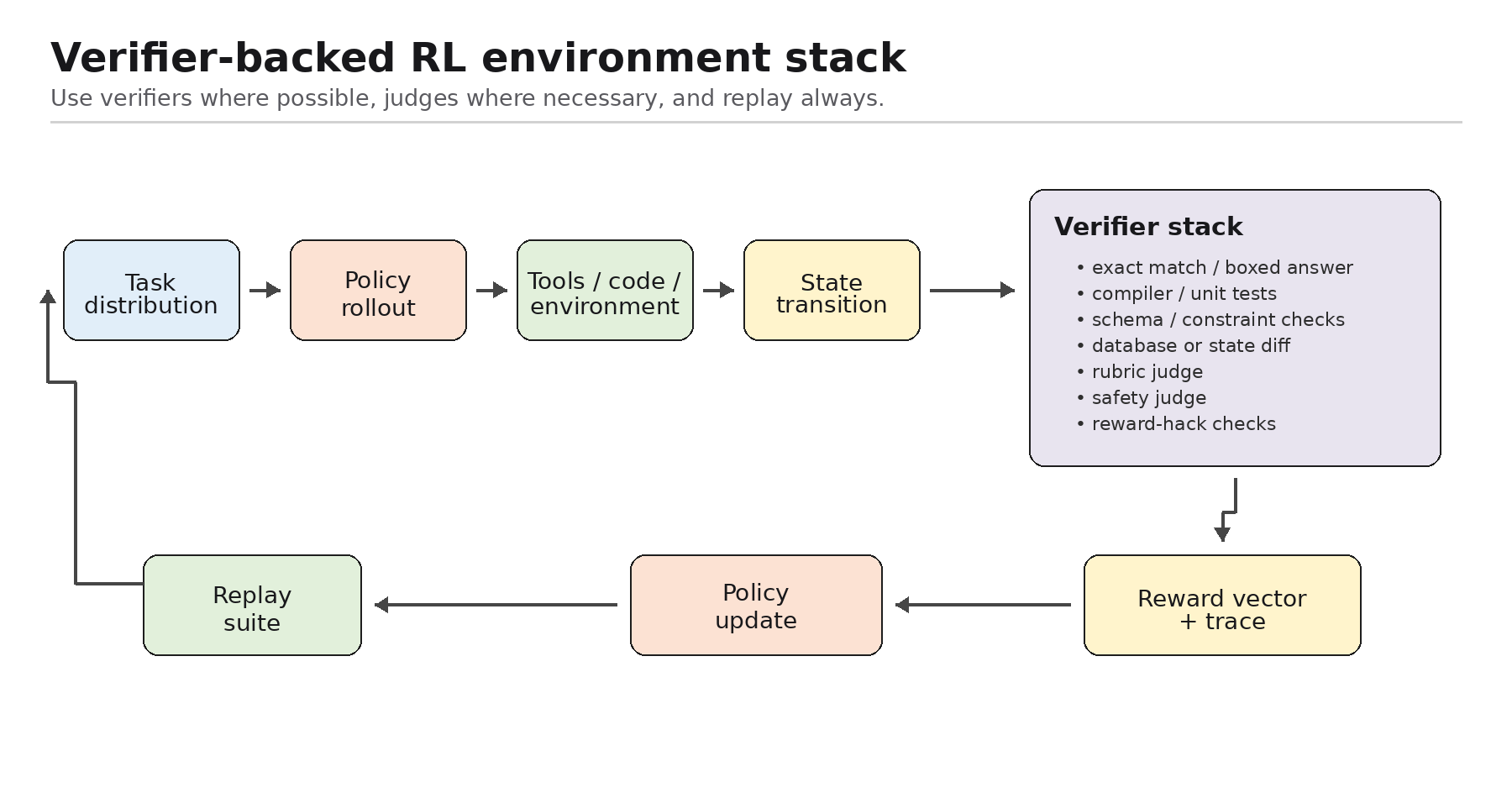
Figure 5. A verifier-backed RL environment stack.
The engineering lesson is simple:
Use verifiers where possible.
A scalar reward without provenance is dangerous. A judge without calibration is dangerous. An environment without anti-hacking checks is dangerous. A rollout without replay is lost data.
7. Context engineering is runtime data engineering
The same data problem now appears at inference time.
Prompt engineering asks: what should I say to the model?
Context engineering asks: what information state should the model see before the next action?
That information state includes instructions, task state, retrieved evidence, examples, memories, tool schemas, tool outputs, prior decisions, constraints, citations, rubrics, and open uncertainties.
This is not cosmetic. It is runtime curation. An agent context window is a temporary dataset assembled for one forward pass.
If the context is stale, the model reasons from stale evidence.
If the context is polluted, the model amplifies pollution.
If the context is too large, the model gets distracted.
If the context omits a constraint, the model violates it.
If the context includes sensitive data unnecessarily, the system creates avoidable risk.
If the context is over-compressed, the model loses the structure it needed.
ACE, or Agentic Context Engineering, is one of the most relevant recent papers here. It treats contexts as evolving playbooks rather than static prompts. ACE uses a Generator, Reflector, and Curator to accumulate, refine, and organize strategies through incremental delta updates rather than monolithic rewrites. Across agent and finance benchmarks, ACE reports +10.6% on agents and +8.6% on finance, while adapting without labeled supervision by using execution feedback. [11]
The most important ACE result is the failure mode: context collapse. In one AppWorld case study, a context at step 60 contained 18,282 tokens and achieved 66.7 accuracy. One rewrite collapsed it to 122 tokens, and accuracy fell to 57.1, worse than the 63.7 baseline without adaptation. [11]
That is epiplexity in practice. Compression removed useful structure. Shorter was not better. Cleaner was not better. A summary destroyed operational knowledge.
The right rule is not “use more context.” The right rule is: preserve useful structure while controlling distraction, staleness, privacy, and cost.
ACE’s cost data is also useful. On AppWorld offline adaptation, ACE reduced latency by 82.3% and rollouts by 75.1% versus GEPA. On online FiNER, it reduced latency by 91.5% and token cost by 83.6% versus Dynamic Cheatsheet. That happened because ACE used incremental delta updates and non-LLM merging/deduplication instead of repeatedly rewriting the whole context. [11]

Figure 6. Context engineering as runtime data curation.
Retrieval should optimize utility, not similarity
Most RAG systems still retrieve by semantic similarity. That is not enough for in-context learning.
ICLERB reframes retrieval for ICL as a recommendation problem: retrieve the documents that maximize downstream LLM utility, not merely the documents most semantically similar to the query. Its benchmark evaluates retrievers by whether retrieved contexts improve LLM accuracy in ICL settings. [12]
The results are important. ICLERB found that rankings diverge from MTEB-style retrieval rankings, meaning strong search embeddings are not necessarily strong ICL context selectors. It also found that fine-tuning for semantic similarity can be detrimental for ICL utility in some cases. [12]
The RLRAIF method goes further: it fine-tunes a retriever using LLM feedback as a reward signal. With only about 10K DPO values, estimated at 5M tokens, and a small adapter trained on a consumer GPU, the RLRAIF reranker achieved 0.7238 nDCG@10 and 0.7225 nDCG@50, outperforming much larger models such as bge-en-icl and NV-Embed-v2 on ICLERB. [12]
The practical implication is direct: do not evaluate retrieval only by relevance. Evaluate whether the retrieved context changes the answer.
For agents, the retrieval target is not top-k similar chunks. It is the minimum sufficient evidence pack for the next decision.
Likely useful in the evidence pack
task state; hard constraints; source-grounded facts
prior decisions; tool schemas; recent tool outputs
similar solved cases; known failure modes; rubrics; unit tests
Usually exclude or isolate
duplicate chunks; stale state; irrelevant logs
raw tool dumps; summaries that erase operational detail
sensitive data not needed by the model
Long-context benchmarks show why this matters
Needle-in-a-haystack is too easy.
RULER was designed because vanilla needle tests measure superficial retrieval. It adds diverse needle types, multiple needles, multi-hop tracing, aggregation, and configurable length/task complexity. In its evaluation of 17 long-context LMs across 13 tasks, many models that were nearly perfect on vanilla needle-in-a-haystack degraded sharply as length and complexity increased; only about half maintained satisfactory performance at 32K despite claiming 32K+ context. [13]
NoLiMa removes literal overlap between the question and the relevant evidence. That matters because many long-context systems can exploit lexical matching rather than understanding. At 32K context, 11 evaluated models dropped below 50% of their short-context baselines, and GPT-4o dropped from 99.3% to 69.7%. [14]
LongBench v2 tests deeper long-context reasoning with 503 multiple-choice questions, contexts from 8K to 2M words, and six categories including single-document QA, multi-document QA, long in-context learning, long-dialogue history, code-repository understanding, and structured-data understanding. Human experts reached 53.7% under a 15-minute constraint; the best direct-answer model reached 50.1%, while o1-preview reached 57.7% with longer reasoning. [15]
For coding agents, ContextBench is more directly operational. It contains 1,136 issue-resolution tasks from 66 repositories across eight programming languages, with human-annotated gold contexts. It measures context recall, precision, and efficiency across agent trajectories. [16]
That gives us a practical evaluation stack for context engineering:
RULER → synthetic long-context retrieval, tracing, aggregation
NoLiMa → long-context retrieval without lexical shortcuts
LongBench v2 → realistic deep long-context reasoning
ContextBench → coding-agent context recall, precision, efficiency
ICLERB → utility of retrieved examples/documents for ICL
AppWorld/ACE → adaptive context and agent memory under feedback
The conclusion is direct: context must be evaluated as a data product.
Every context policy should be ablated:
remove a memory component
change the retriever
change the reranker
change the compression method
change the evidence budget
change tool-output handling
change citation requirements
replay the same episodes
measure success, grounding, latency, token cost, and regressions
8. Production traces are the next dataset
The highest-value data often appears after deployment.
Production traces show what users actually ask, what the model retrieves, which tools it calls, where it fails, which evidence it ignores, which judge disagrees, where policies are ambiguous, and where the model sounds confident without being grounded.
Those traces should not disappear into logs. They should become training, evaluation, context, and reward artifacts.
The loop is:
observe → classify → verify → compile → replay → promote
A failure can compile into many things:
bad answer → corrected SFT example
bad retrieval → new chunking rule or index update
bad tool call → tool-use trajectory or schema constraint
bad judgment → rubric update or judge calibration item
unsafe response → safety eval and reward example
missing knowledge → source update and retrieval test
long-context miss → context benchmark replay
agent dead-end → environment transition test
This is the practical version of the Verifier-Compiler Loop: observe traces and outcomes, evaluate with checks and judges, intervene safely, then compile expert decisions into a versioned behavioral contract. [20]
Do not just patch the prompt. Classify the failure. Compile the correction. Replay the system. Promote only when the change improves the target behavior without regressing adjacent behavior.
9. Data quality needs contracts
A serious LLM or agent program needs data contracts. Not bureaucracy. Engineering contracts.
For every dataset:
Dataset name:
Training stage:
Source classes:
License / usage constraints:
Freshness window:
Extraction method:
Filtering rules:
Dedup method:
PII / policy filters:
Contamination checks:
Capability tags:
Difficulty tags:
Mixture weight:
Verifier:
Judge model / rubric:
Known failure modes:
Evaluation suite:
Ablation evidence:
Owner:
Promotion criteria:
Rollback criteria:
For every context policy:
Context sources:
Retrieval policy:
Reranking objective:
Memory write policy:
Compression policy:
Isolation boundaries:
Citation requirements:
Tool-output handling:
Sensitive-data policy:
Staleness policy:
Replay evals:
Observed regressions:
For every RL environment:
Task distribution:
Environment interface:
Allowed tools:
State transition rules:
Reward components:
Verifier implementation:
Judge model and version:
Rubric:
Anti-hacking tests:
Timeouts and budgets:
Replay set:
Human escalation path:
This is where production AI becomes engineering rather than prompt folklore.
10. Conclusion
The next wave of progress will not come only from larger models.
It will come from better data control.
Better extraction.
Better cleaning.
Better deduplication.
Better filtering.
Better source mixtures.
Better ordering.
Better synthetic compilers.
Better long-context curricula.
Better context playbooks.
Better verifier-backed environments.
Better reward models.
Better replay systems.
Better governance.
The teams that win will not be the teams with the largest pile of tokens.
They will be the teams that know which data changes behavior, why it changes behavior, how to measure that change, and how to keep improving it without corrupting the system.
Data is not just the input to training.
Data is the control surface.
References
[1] Epiplexity: Information Theory for Computationally Bounded Learners. https://arxiv.org/abs/2601.03220
[2] FineWeb: Decanting the Web for the Finest Text Data at Scale. https://arxiv.org/html/2406.17557v1
[3] Apple Machine Learning Research: The Data-Quality Illusion. https://machinelearning.apple.com/research/data-quality-illusion
[4] NVIDIA Nemotron Nano 2 Technical Report. https://arxiv.org/html/2508.14444v2
[5] Qwen3 Technical Report. https://arxiv.org/html/2505.09388v1
[6] RegMix: Data Mixture as Regression. https://arxiv.org/abs/2407.01492
[7] DataComp-LM: In Search of the Next Generation of Training Sets for Language Models. https://arxiv.org/abs/2406.11794
[8] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. https://arxiv.org/html/2501.12948v1
[9] Kimi K2 Technical Report. https://arxiv.org/html/2507.20534v2
[10] NVIDIA Nemotron 3 Super Technical README. https://github.com/NVIDIA-NeMo/Nemotron/blob/main/docs/nemotron/super3/README.md
[11] ACE: Agentic Context Engineering. https://arxiv.org/html/2510.04618v1
[12] ICLERB and RLRAIF: Learning to Retrieve In-Context Examples by Utility. https://arxiv.org/html/2411.18947v1
[13] RULER: What’s the Real Context Size of Your Long-Context Language Models?.
https://openreview.net/forum?id=kIoBbc76Sy
[14] NoLiMa: Long-Context Evaluation Beyond Literal Matching.
https://openreview.net/forum?id=0OshX1hiSa
[15] LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-Context Multitasks. https://arxiv.org/abs/2412.15204
[16] ContextBench: A Benchmark for Measuring Context Engineering in Coding Agents. https://arxiv.org/html/2602.05892v2
[17] Instruction Pre-Training: Language Models are Supervised Multitask Learners. https://arxiv.org/html/2406.14491v1
[18] MAmmoTH2: Scaling Instructions from the Web. https://arxiv.org/html/2405.03548v3
[19] Web Reconstruction: Reconstructing Instruction Data from the Web. https://arxiv.org/html/2504.15573v1
[20] The Verifier-Compiler Loop. https://www.equationblog.com/p/the-verifiercompiler-loop-turning