

The Verifier–Compiler Loop: Turning Human Preferences into Production Agent Judgment
Why verifier–compiler loops matter more than another prompt patch

Agents do not usually fail in production because a prompt suddenly stopped working. They fail because a workflow that looked 98% fine in isolation turns into 30 turns, six tool calls, two handoffs, a compliance boundary, and a frustrated human on the other side.
That is the march-of-nines problem (as originally described by Andrey Karpathy). In a long workflow, tiny per-step defects compound into very large end-to-end losses. At 100 steps, a 1% failure rate at each step leaves only about 36.6% end-to-end success; even 0.1% still leaves only about 90.5%. For customer service, regulated operations, and multi-agent workflows, that gap is the difference between a promising demo and a system the business can trust.
The practical implication is that production reliability should be treated as an error-correction problem. Better base models help, but they are only part of the story. The system also needs a way to observe what happened, judge it against the organization’s standards, intervene safely when necessary, replay changes before release, and keep durable evidence of what changed and why.
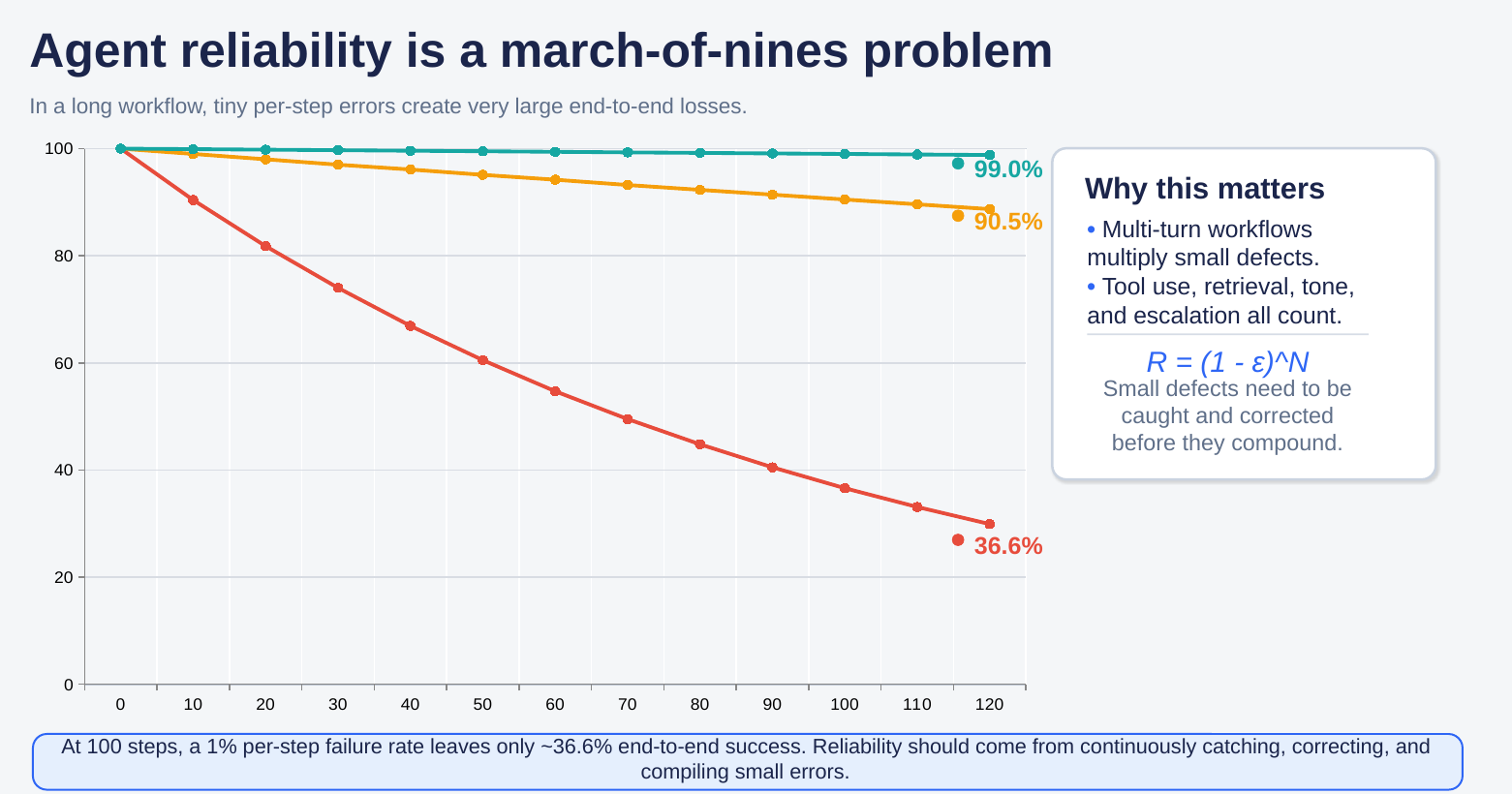
Figure 1. In long workflows, small per-step errors compound into large end-to-end losses.
Reliability should come from continuously catching, correcting, compiling, and proving small errors — not from hoping one prompt patch will cover every edge case.
Production failures are not only knowledge failures
A surprisingly large share of production failures are not missing-fact failures. The agent may know the product terms, retrieve the right document, or call the right tool and still fail the institution.
Four surfaces matter in practice: missing knowledge, institutional judgment, user affect, and evidence. A response can be factually correct but still violate policy, choose the wrong level of certainty, worsen the user’s emotional trajectory, or leave the team unable to reconstruct what happened well enough to approve a safe fix.
Missing knowledge: The agent lacks a fact, a tool result, or an updated policy exception.
Judgment misalignment: The facts are present, but the trade-off between speed, certainty, empathy, policy, or escalation is wrong.
Affect regression: The reply is technically valid but increases frustration, distrust, or confusion.
Evidence gap: The team cannot replay the episode, inspect the rewrite, or approve the next release with confidence.
A banking example makes the distinction concrete. An assistant can know the product, know the account state, and still reply in a way that is too dismissive, too certain, or too slow to escalate.

Figure 2. A customer-facing answer can know the facts and still miss the institution’s judgment on policy, style, affect, or action.
Judgment should be explicit
One way to make this tractable is to keep execution knowledge and institutional judgment separate, but versioned together. Skills describe how the work gets done: task-specific success criteria, approved procedures, tool permissions, and required evidence. Judgment describes how the organization wants that work done: risk boundaries, policy rules, quality bars, tone, trade-offs, escalation behavior, and release gates.
That separation matters because business policy changes faster than workflow logic. If a new escalation rule or compliance boundary requires rewriting every skill from scratch, the system becomes brittle. If judgment is explicit, global changes can be compiled once and enforced across many workflows.
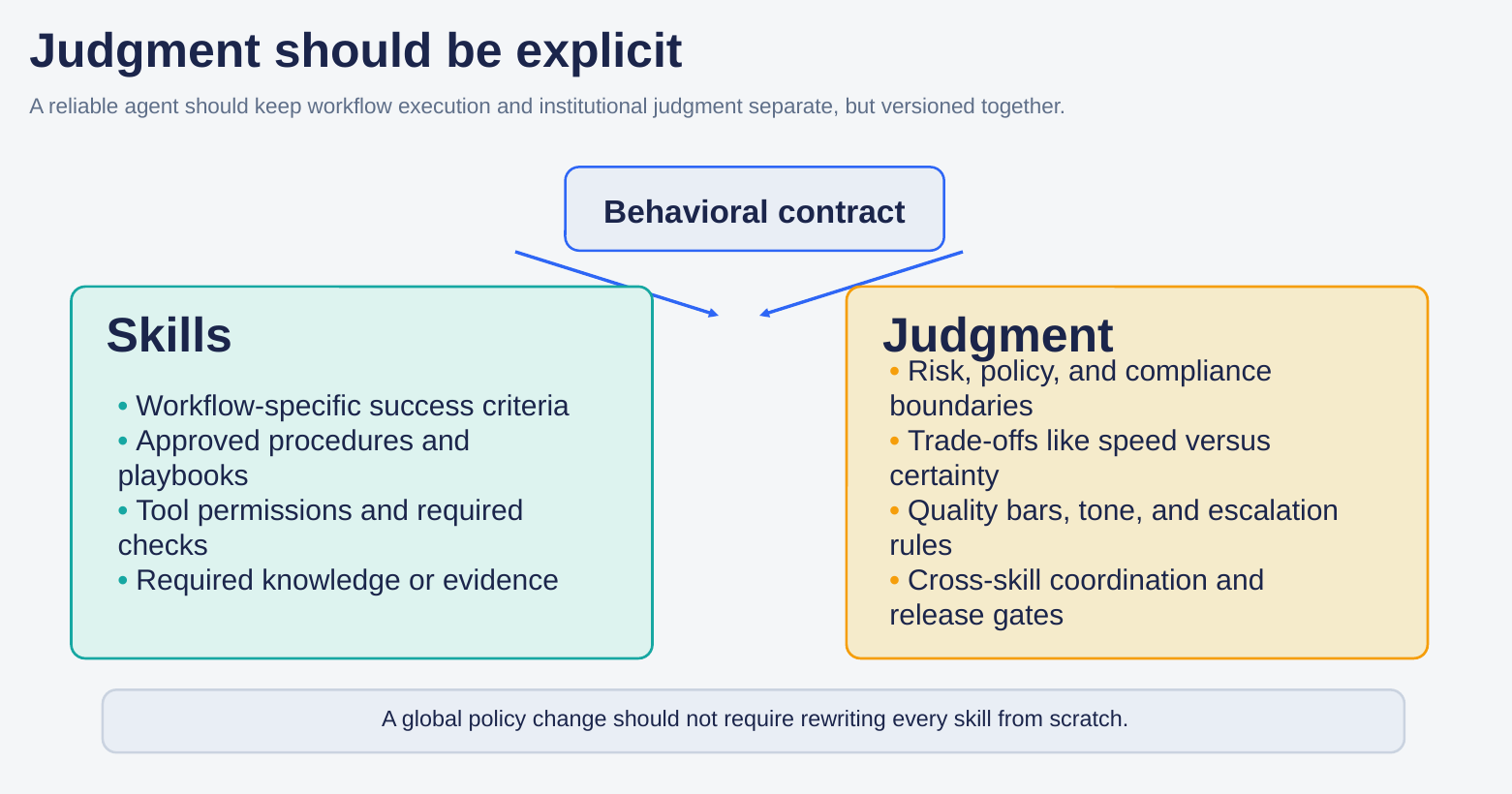
Figure 3. A reliable agent should keep workflow execution and institutional judgment separate, but versioned together as a behavioral contract.
An example of a production flywheel
A useful production flywheel is not a vague analytics dashboard. It turns one live interaction into an ordered, auditable episode. In one practical pattern, a conversation becomes: user message → draft response → affect and intent signals → initial evaluation → rewrite decision → post-rewrite evaluation → delivered message.
Once that structure exists, the same episode can be replayed later, reviewed by humans, approved or rejected, and compiled into the next version of the behavioral contract. Runtime interventions can stay conservative — rewrite, route, pause, slow-halt, or escalate — while the offline loop decides what should become a durable product change.
This is the shift from prompt folklore to production engineering. A corrected response is useful at the moment; a replayable, reviewable correction is useful week over week.
A few operating patterns tend to work
Observe real traces, not only synthetic eval sets.
Keep affect, policy, and tool behavior in the same episode view.
Replay proposed changes before release rather than patching blindly in production.
Treat approvals and evidence as part of the product, not as after-the-fact documentation.
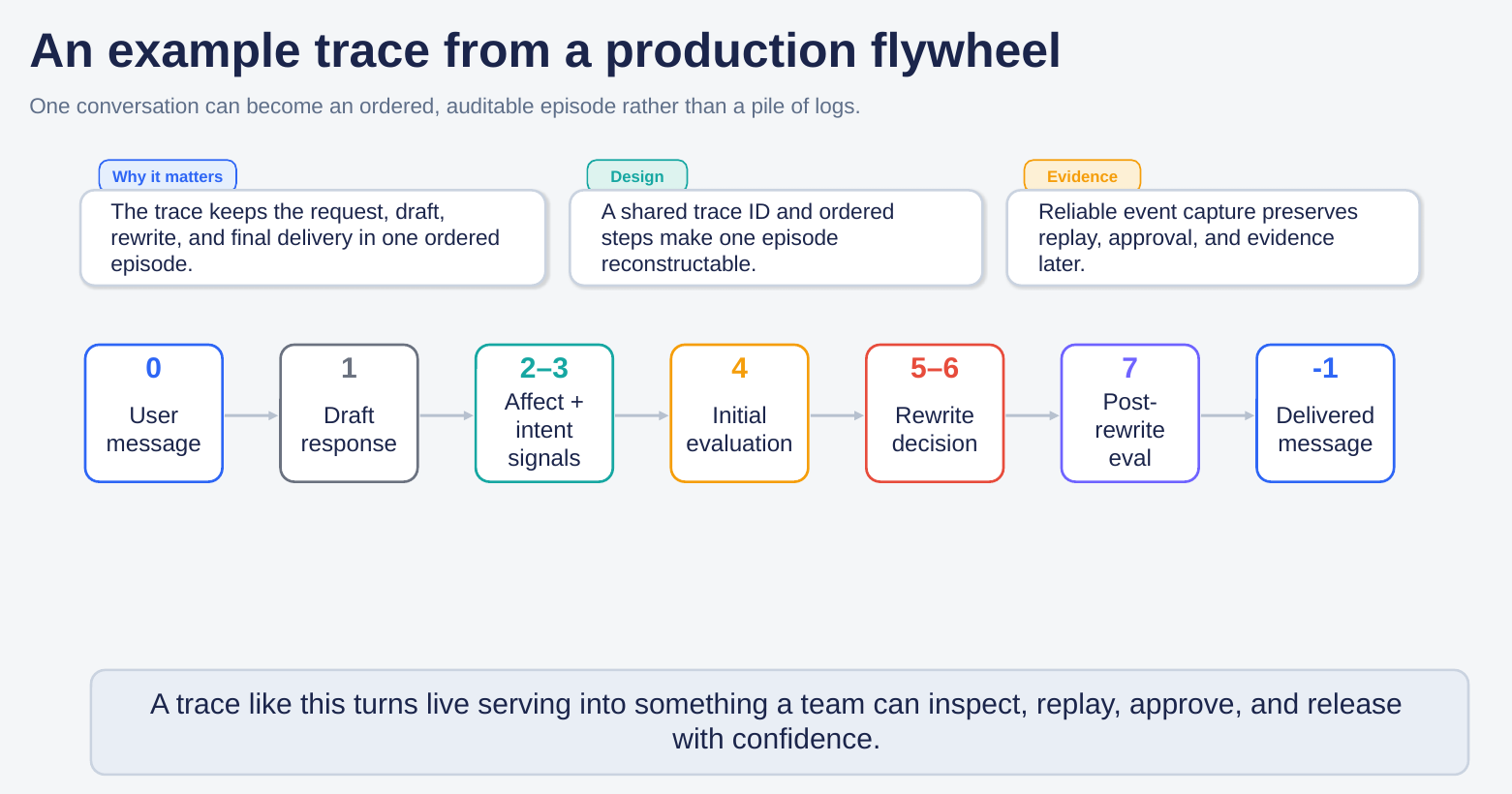
Figure 4. A production flywheel turns one conversation into an ordered, replayable episode that can be inspected, approved, and released with confidence.
Judge quality now depends on calibration
Recent judge research points in two directions at once. On one hand, judges are improving. Benchmarks such as JudgeBench and RewardBench 2 are making judge quality easier to measure, while DeepSeek’s GRM / SPCT work suggests that principle generation, critique, and inference-time aggregation can make reward modeling and preference judging much stronger in practice.
On the other side, the field is getting more honest about calibration. Newer 2025–2026 work argues that one raw judge score is not enough. Some evaluators show stable but different “evaluative fingerprints,” meaning they can be internally consistent while still disagreeing systematically with one another. Other papers show that rubric order, pointwise versus pairwise framing, and judge allocation can shift rankings if those choices are left uncalibrated.
The production lesson is simple: one judge should not be the whole control system. High-reliability systems tend to use a judge stack — crisp gates for clear defects, calibrated reasoning judges for nuance, replay for release decisions, disagreement review for hard cases, and humans for the highest-risk boundaries.
The newest question is no longer only “Which judge scores highest on a benchmark?” It is also “Which judge remains stable, interpretable, and properly calibrated inside a release process?”
User simulation can help, but only with calibration
User simulation is becoming necessary because replay without synthetic users does not cover enough edge cases. Recent work such as SimulatorArena suggests that profile-conditioned simulators can track human ratings reasonably well on some multi-turn tasks, especially when the simulator has access to richer user profiles rather than a generic system prompt.
But simulation should not be treated as ground truth. Lost in Simulation is the warning label: simulator choice can materially change measured success, and simulated populations can drift away from real human behavior. The practical pattern is simulation plus calibration — use synthetic users to widen test coverage, then measure the gap to hold-out human traces and correct for it.
Auditability should be part of the product
If the team cannot reconstruct which draft was blocked, which rewrite was sent, what evidence triggered the intervention, and which version of the behavioral contract approved the change, then it does not really have a production flywheel. It has prompt folklore.
Auditability is what turns one corrected episode into a durable release decision. In practice, that usually means keeping trace and event correlation, judge verdicts, rewrites, replay results, approval records, and release decisions together. The goal is not paperwork. The goal is to make the next change easier to inspect, safer to ship, and easier to trust.
How this connects to my ODSC East talk
At ODSC East 2026, I’ll go deeper into the mechanics behind this pattern: how judge stacks can be calibrated, how runtime interventions can be chosen without creating new risk, how replay should precede release, and how week-over-week improvements can turn human preferences into durable production agent judgment.
The talk title is “The Verifier–Compiler Loop: Turning Human Preferences into Production Agent Judgment.” This article only sketches the frame. The session will go much deeper into the system design and operating model behind it.
Selected references