

Who Owns Engineering Judgment?
Human attention, model budgets, and the control plane for AI-native software organizations

Price per token is not a cost model. It is an input to a cost model.
The AI engineering conversation is still too focused on the wrong budget.
Tokens, model pricing, and vendor leverage all matter. But the real budget is not tokens.
The real budget is senior human attention: the moments when a model output needs correction, interpretation, architectural judgment, security review, release approval, customer-risk ownership, or institutional context.
That is where the system breaks.
There is an even deeper question underneath it: As models get better, who owns engineering judgment?
One answer is: the model vendors.
That answer is less crazy than people want to admit.
Coding agents are moving beyond autocomplete into planning, design, implementation, testing, review, deployment, and operations. Full software development lifecycle is increasingly in scope for AI assistance, including planning, design, development, testing, review, and deployment. Agents can draft implementations, modify code across many files, fix build errors, write tests, and produce diff-ready change sets.
So yes, more workflow logic will move closer to the model.
That includes planning, review, risk detection, test selection, escalation, human handoff, evidence production, and learned standards of “good engineering.”
The question is not whether this happens. It already has. The question is what companies should still own?
The uncomfortable fork
There are two lazy versions of the future.
The first says:
Model vendors will own everything.
They have the data. They have the compute. They have the distribution. They have the feedback loop. They will absorb all relevant engineering intelligence, including when to involve humans. Your internal workflows will become a thin wrapper around their agents.
The second says:
Models are just utilities.
They are like electricity or cloud compute. Useful, interchangeable, commoditized. The real value stays entirely in business context, process, data, and execution.
Both are partially true.
Both are incomplete.
The more interesting version is this:
Model vendors will own more generic intelligence than most companies expect. Great companies will still own situated intelligence: context, authority, verification, accountability, and the compounding memory of their own decisions.
That is the distinction I care about.
Not “AI versus human.”
Not “frontier model versus cheap model.”
Not “central platform team versus product teams.”
The real boundary is:
Let the model own heuristics. Keep institutional authority outside the model.
The price card has become strategically relevant again
For a while, it was fashionable to say model cost would round to zero.
Maybe someday. Not yet.
As of June 15, 2026, public token prices still vary by orders of magnitude across model families, context tiers, output volume, caching, priority mode, batch mode, and whether you are using a seat plan, credit system, or direct API.
The point is not to memorize today’s prices. They will change. The point is that model choice is now an operating decision.
OpenAI’s public API page currently lists GPT-5.5 at $5.00 per million input tokens, $0.50 per million cached input tokens, and $30.00 per million output tokens under standard processing for shorter context; it lists GPT-5.4 at $2.50 / $0.25 / $15.00 and GPT-5.4 mini at $0.75 / $0.075 / $4.50 for input, cached input, and output respectively.
Anthropic’s Claude API pricing page currently lists Claude Fable 5 at $10 input / $1 cache hit / $50 output per million tokens, Claude Opus 4.8 at $5 / $0.50 / $25, Claude Sonnet 4.6 at $3 / $0.30 / $15, and Claude Haiku 4.5 at $1 / $0.10 / $5. The same page says prompt-cache reads cost 0.1x base input price and batch processing applies a 50% discount to both input and output tokens.
Google’s Gemini API pricing currently lists Gemini 3.1 Pro Preview at $2 input / $12 output per million tokens for prompts up to 200K tokens, and $4 / $18 above 200K. It also lists Gemini 3.5 Flash at $1.50 / $9, Gemini 3.1 Flash-Lite at $0.25 / $1.50, and Gemini 2.5 Flash-Lite at $0.10 / $0.40, with output pricing including thinking tokens.
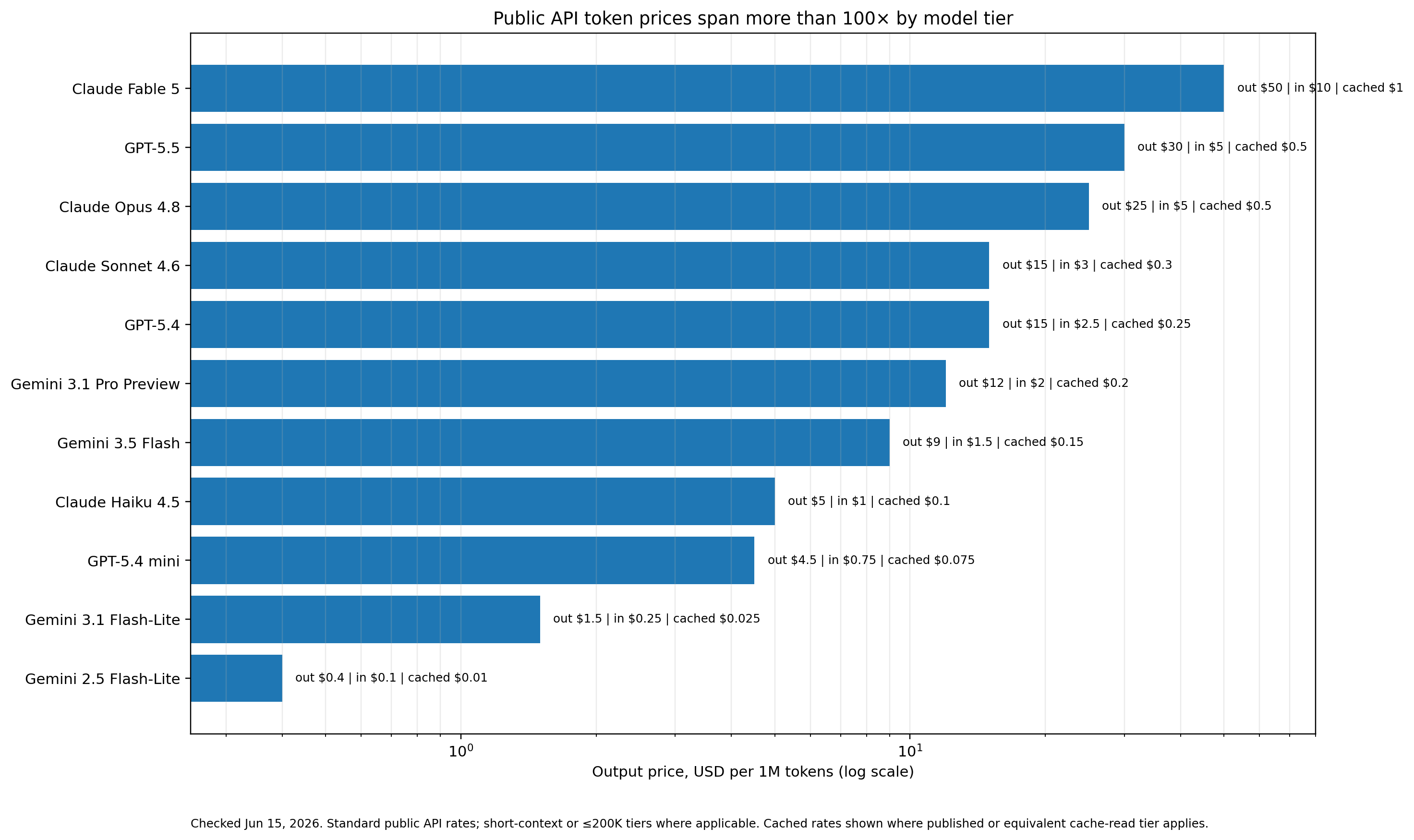
The first data point executives should internalize: the same million-token workflow can cost cents, dollars, tens of dollars, or more depending on model, context, output, caching, priority, and tool mode.
The second data point matters more: the token bill is often not the expensive part.
The expensive part is the human recovery loop.
Price per token is the wrong denominator
The wrong denominator is: cost per token
The better denominator is: cost per accepted, reviewed, shipped change
A cheaper model that takes three attempts, creates drift, burns an hour of senior review, and leaves uncertainty around a risky migration may be more expensive than a frontier model that completes the work cleanly in one pass.
The token bill is visible.
The senior-engineer recovery cost is usually hidden.
The bad loop looks like this:
Human gives a loose prompt.
Agent starts coding.
Human watches nervously.
Agent drifts.
Human interrupts.
Agent patches around the correction.
Tests fail.
Human re-explains the system.
Final diff is stitched together from partial attempts.
That is not autonomy.
That is interrupt-driven delegation.
The better loop looks like this:
Human approves intent, constraints, risks, and success criteria.
Agent produces a plan before implementation.
Human gates the plan.
Agent implements against the approved plan.
A separate review agent attacks the diff.
Output is packaged as evidence.
Human reviews the evidence, resolves judgment calls, and owns merge/release readiness.
Useful discoveries become future context, tests, runbooks, evals, or skills.
The practical target is not “more AI usage.”
The practical target is:
fewer human corrections per accepted diff
fewer repeated attempts
shorter review time
lower escaped-defect rate
higher useful concurrency per senior engineer
more institutional knowledge captured per completed task
That is the engineering budget.
A simple cost model
Here is the model I would use for budgeting:
monthly model cost ≈ fresh input tokens + cached input tokens + output tokens + tool/runtime costs
More specifically:
Fresh input tokens: repo context, prompts, docs, issues, logs, traces.
Cached input tokens: repeated context, stable repo instructions, runbooks, API docs, prior plans.
Output tokens: code, tests, plans, reviews, explanations, retries.
Tool/runtime costs: web search, containers, managed agent runtime, code execution, priority/fast mode, storage, observability.
The simple version:
monthly cost ≈ fresh input MTok × input price + cached input MTok × cache-read price + output MTok × output price + tools
The scary part is output and retries.
The saving grace is caching.
Caching turns stable company context into a cost advantage. Anthropic’s pricing page says prompt-cache reads cost 0.1x base input price and that cache reads pay off quickly after reuse; OpenAI’s pricing page also shows cached-input rates materially below fresh-input rates for its flagship models.
So the first-order governance question is not: How do we cap tokens?
It is: How do we make the same context useful repeatedly without reloading the company from scratch every time?
Planning ranges I would use
Do not treat the following as a benchmark.
Treat it as a planning model.
Also: do not plan any serious AI use case below $100 per user per month.
That does not mean every user will spend $100. It means that below that floor, you are usually not planning for real usage, variance, retries, training, tool overhead, or bursts.
For engineering, I would not plan below $200 per engineer per month.
Again, not every engineer will spend it every month. But if the budget starts below $200, the organization is implicitly designing for toy usage, not production behavior.
OpenAI’s Codex rate card says a typical Codex task using GPT-5.5 may consume 5–45 credits, and that average Codex cost is roughly $100–$200 per developer per month, with large variance depending on model, instances, automations, and fast mode. That is a useful public anchor, but I would still set the engineering planning floor at $200 because real production engineering needs room for variance.
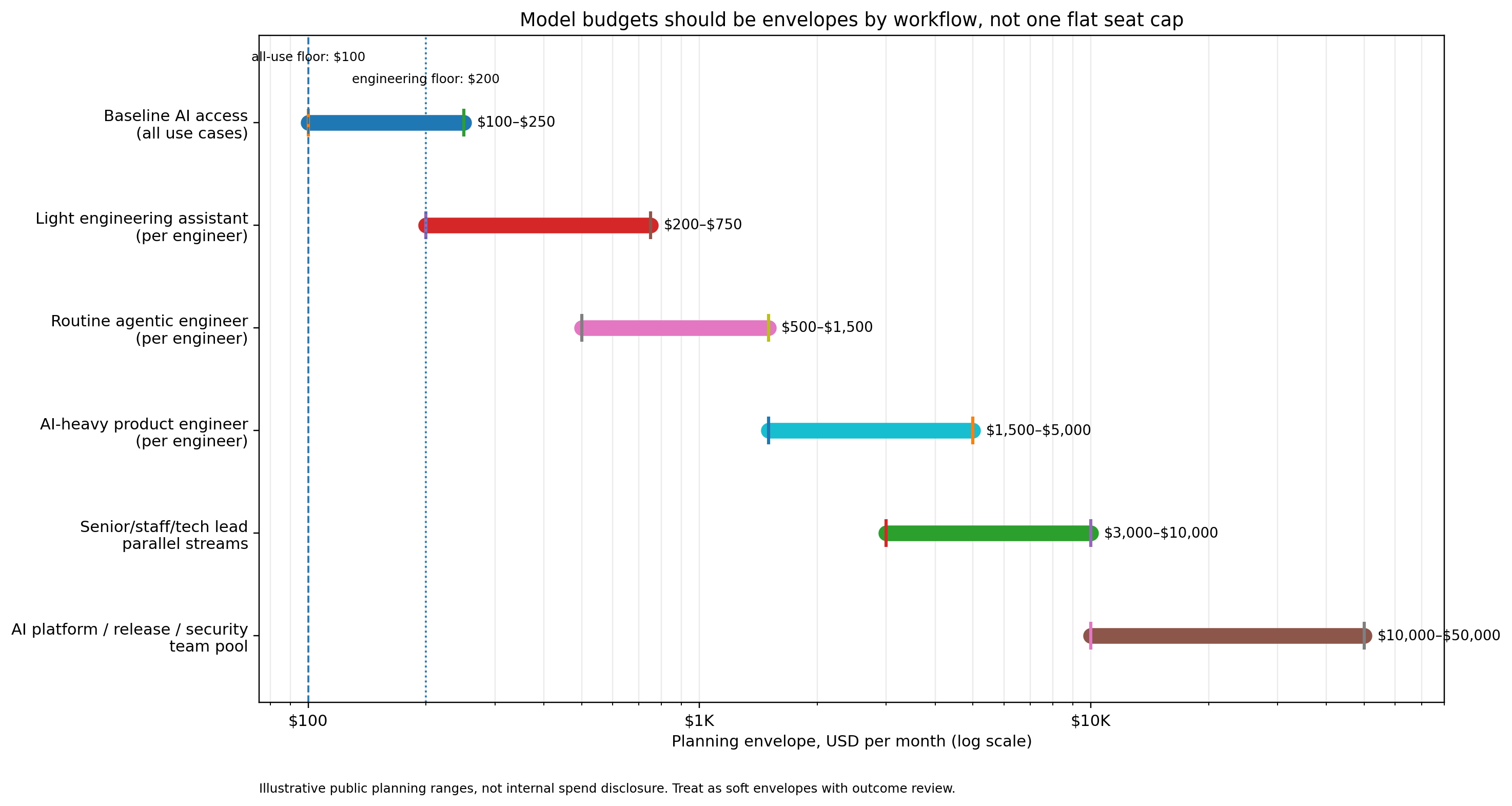
Baseline AI access
Expected range: $100–$250 per user per month
Use for:
general productivity
research
writing
summarization
lightweight analysis
occasional technical help
This is the minimum serious floor. Below this, the budget usually becomes administrative theater.
Light engineering assistant
Expected range: $200–$750 per engineer per month
Use for:
code explanations
small scripts
autocomplete
simple unit tests
light PR summaries
documentation
low-risk helper workflows
This is where engineering access should start. A lower floor encourages underuse, rationing, or avoidance.
Routine agentic product engineer
Expected range: $500–$1,500 per engineer per month
Use for:
daily code generation
test generation
codebase exploration
small refactors
PR summaries
routine debugging
first-pass reviews
This is the zone where agents become part of the daily engineering loop, but not yet the primary implementation substrate.
AI-heavy product engineer
Expected range: $1,500–$5,000 per engineer per month
Use for:
long-running implementation loops
multi-file refactors
design-to-plan-to-code workflows
substantial test generation
repeated review cycles
larger repo context
high cached-context reuse
This is plausible when daily work moves from “assistant” to “delegated workflow.” It should be governed by accepted diffs, review load, and defect outcomes, not by token volume alone.
Senior, staff, or tech lead supervising parallel streams
Expected range: $3,000–$10,000 per user per month
Use for:
architecture exploration
cross-service refactors
high-risk PR review
migration planning
release readiness
adversarial review
parallel agent supervision
incident/post-incident investigation
This is the category where hard caps are most dangerous.
These people amplify many other people and many other agents. Blocking them to save tokens can waste the scarcest resource in the company: senior judgment.
AI platform, release, security, or agent-heavy team pool
Expected range: $10,000–$50,000+ per team per month
Use for:
private evals
routing experiments
skill registries
repo-context services
model comparisons
automated review infrastructure
autonomous regression hunts
release and incident automation
enterprise observability and governance
This should usually be a pooled budget, not a per-seat cap.
Platform, incident, release, and evaluation work are all bursty.
The rule should be: no blank checks, but no dumb throttling during approved high-leverage windows.
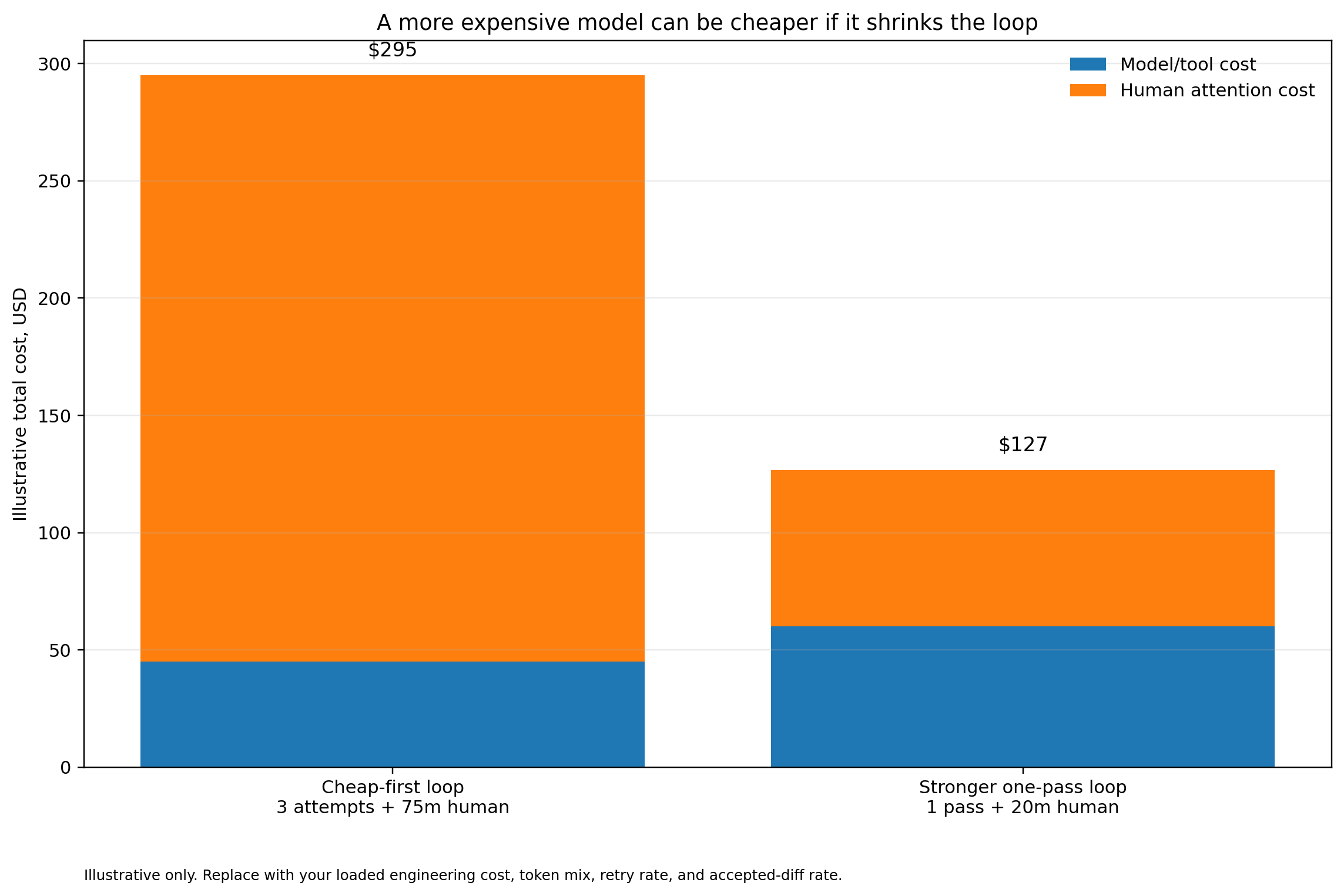
The danger of false economy
A more capable model can be cheaper even when its tokens are more expensive.
This feels counterintuitive only if you measure the wrong thing.
Assume a cheaper model takes three attempts, creates uncertainty, and consumes 75 minutes of senior review.
Assume a stronger model costs more in tokens but finishes cleanly and consumes 20 minutes of review.
At a fully loaded senior-engineering cost of even $150–$300 per hour, the second path can easily be cheaper.
Not because the tokens are cheaper.
Because the loop is cheaper.
Use cheaper/default models for bounded work:
formatting
summarization
low-risk docs
simple scaffolding
rote transformations
test naming
Use stronger models when the value is uncertainty reduction:
ambiguous architecture
cross-service changes
security-sensitive paths
data migrations
release readiness
incident response
adversarial review
poorly documented internal systems
The mistake is not spending too much on frontier models.
The mistake is spending frontier tokens where cheap models are enough, then being cheap where a better model would save senior attention, reduce rework, or avoid defects.
The question is not: What is the cheapest model that can attempt this?
The better question is: What is the cheapest complete loop that can get this safely accepted?
AI amplifies the engineering system you already have
DORA’s 2025 research found near-universal AI adoption among software professionals: 90% of respondents reported using AI at work, and more than 80% believed it increased productivity. The same Google Cloud summary notes that 30% reported little or no trust in AI-generated code, which is exactly the tension engineering leaders need to design around.
That matches what technical leaders see in practice.
AI does not fix the engineering system.
It amplifies it.
If your specs are crisp, tests are fast, ownership is clean, docs are usable, review norms are strong, and release paths are well instrumented, agents multiply the system.
If your specs are ambiguous, tests are flaky, docs are stale, ownership is fuzzy, and senior review is overloaded, agents multiply that too.
More generated code without more validation capacity is not productivity.
It is inventory.
The model should not become the control plane
There is a subtle danger as agents get more competent.
The workflow starts cleanly:
model proposes a plan
model writes code
model runs tests
model reviews the diff
model summarizes risk
model recommends human approval
Then the next step is tempting:
model decides whether human approval is needed
Then:
model decides which human
model decides whether evidence is sufficient
model decides whether a policy applies
model decides whether release is safe
At that point, the model is no longer just a cognitive engine.
It is becoming an authority layer.
This is where I would be conservative.
OpenAI’s Model Spec is a useful public example of how much behavior-level logic is moving into models: instruction following, conflict resolution, intended defaults, safety boundaries, and agentic side-effect control. OpenAI describes the Model Spec as a formal framework for desired model behavior and a target for training and evaluation, while also saying it is not a claim that models behave that way perfectly today.
That work is necessary.
It also proves the point: model behavior is itself a control surface.
If your engineering workflow depends on hidden model defaults, provider-side routing, or behavior updates you cannot inspect, you do not really own the control plane.
You are renting it.
The answer is not to distrust model vendors by default.
The answer is to separate intelligence from authority.
The model can advise.
The system must decide.
The model can classify.
The policy layer must enforce.
The model can produce evidence.
The evidence standard must be external.
The model can remember patterns.
The company must own durable memory.
Heuristics inside the model, invariants outside the model
This is the cleanest boundary I see today.
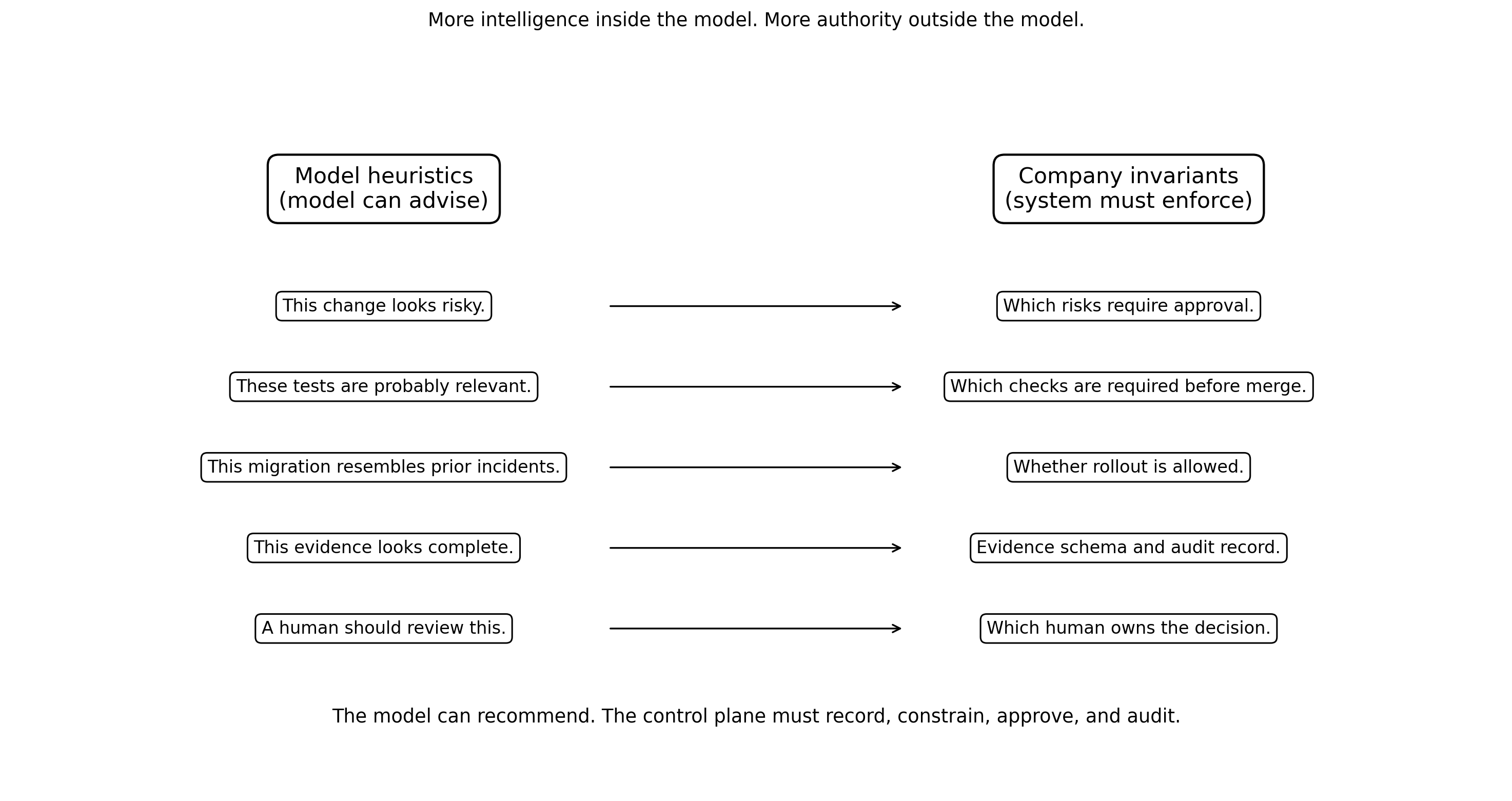
A heuristic is: this looks like a security-sensitive change
An invariant is: security-sensitive changes require named approval, passing checks, rollback notes, and an audit trail
A heuristic is: these tests are probably relevant
An invariant is: no merge without required checks
A heuristic is: this migration resembles prior incidents
An invariant is: customer-data migrations require staged rollout and post-release monitoring
A heuristic is: this evidence package looks complete
An invariant is: every agent-authored PR records the model, prompt/context version, tools used, tests run, unresolved risks, and human approver
A heuristic is: a human should review this
An invariant is: which human, under what SLA, with what responsibility
This matters because otherwise the model becomes the invisible control plane.
And that is the failure mode.
Not “AI writes bad code.”
That is annoying, but manageable.
The worse failure mode is decision laundering:
The model makes a judgment.
The human rubber-stamps it.
The audit trail says “human approved.”
Nobody can reconstruct where the real decision came from.
That is how organizations lose engineering memory while pretending to gain productivity.
Security makes this boundary non-optional
Prompt injection is not a side issue. It is a reminder that LLMs are not normal software components.
The UK National Cyber Security Centre argues that prompt injection is better treated not as normal code injection, but as exploitation of an “inherently confusable deputy.” OWASP’s 2025 Top 10 for LLM and generative AI applications lists prompt injection, sensitive information disclosure, supply-chain risk, data and model poisoning, improper output handling, excessive agency, system prompt leakage, vector and embedding weaknesses, misinformation, and unbounded consumption.
This has a direct implication for engineering agents: never make the model its own permission system.
A model with tool access is powerful.
It is also confusable.
The system needs hard constraints outside the model:
permission boundaries
sandboxing
approval gates
allowlists and denylists
policy checks
secret handling
destructive-operation stops
release gates
audit logs
reproducible evidence
If a model can create code, run code, read internal docs, open tickets, comment on PRs, call tools, inspect logs, and recommend releases, then the model is no longer “just chat.”
It is part of the engineering system.
Treat it that way.
Every non-trivial agent task should start with a plan
Coding agents should not jump from prompt to diff for non-trivial work.
The first artifact should be a plan.
A useful plan names:
affected files and services
assumptions
open questions
sequencing
expected tests
risk areas
migration concerns
rollback concerns
expected evidence before review
This is not bureaucracy.
This is leverage.
A senior engineer can review a plan much faster than they can reverse-engineer a bad branch.
Plan review is where humans catch the shape of the work before the model spends tokens and creates state.
Then implementation happens against the approved plan.
Then a separate review pass attacks the implementation.
Then the output is packaged as evidence.
Then the human reviews the evidence, not just the diff.
OpenAI’s AI-native engineering guide makes a similar operational point in its getting-started checklist: start with well-specified tasks, have the agent use a planning tool or write a PLAN.md, check that commands succeed, and iterate on an AGENTS.md file that unlocks loops like running tests and linters.
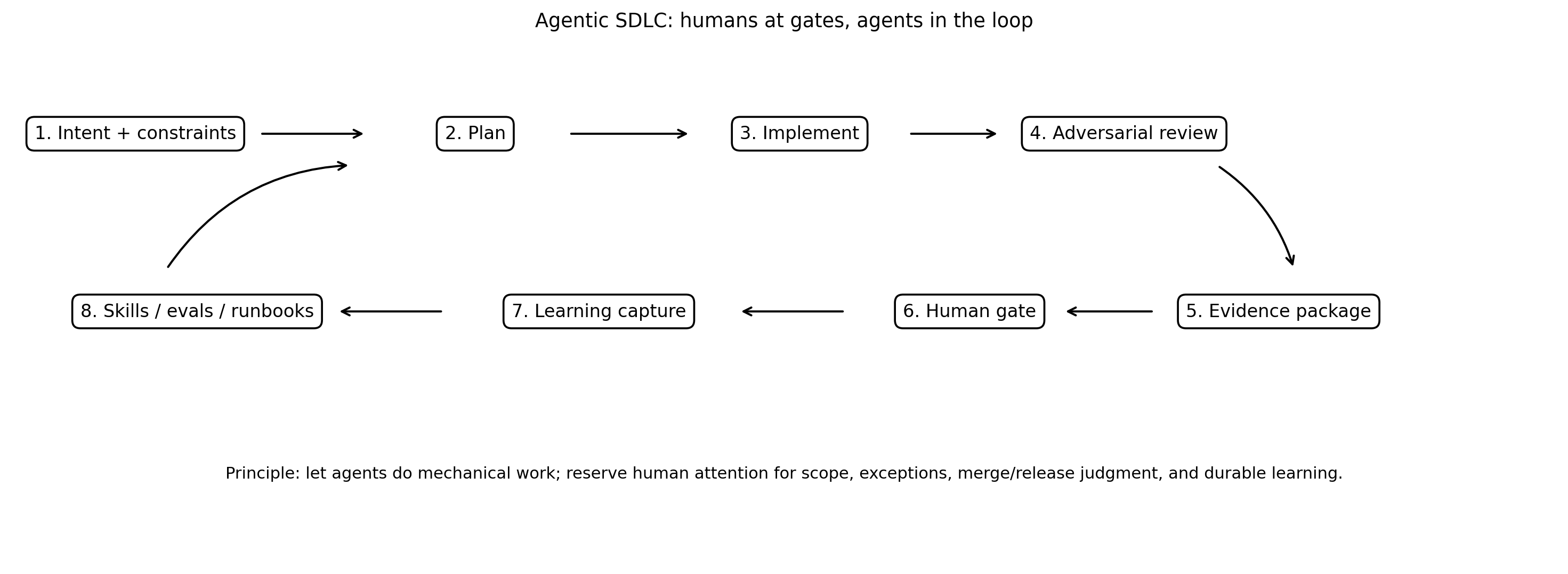
The minimum evidence package should include:
plan
diff summary
tests run
failing tests
unresolved questions
risk assessment
security notes
performance notes
rollout notes
rollback notes
model and context version
tool actions taken
This is the practical version of “human at the gates.”
Without the evidence package, the reviewer has to reconstruct the story.
With it, the reviewer can spend judgment where judgment matters.
“Human in the loop” is too vague
The phrase “human in the loop” can mean anything.
It can mean thoughtful supervision.
It can also mean a senior engineer constantly babysitting a model, interrupting it, correcting it, rerunning tests, unwinding drift, and manually stitching together a final diff.
That is not autonomy.
That is interrupt-driven delegation.
The human should not be in the gears.
The human should be at the gates.
Before work starts
The human gate is scope:
product intent
constraints
blast radius
test strategy
migration risk
open questions
During work
The human gate is exception handling:
repeated failure
ambiguity
high-risk files
destructive operations
security-sensitive changes
missing evidence
Before merge
The human gate is judgment:
architecture
maintainability
security
performance
user impact
rollout plan
rollback path
After release
The human gate is responsibility:
customer impact
incident response
follow-up prioritization
what should become durable organizational memory
The model should do the mechanical reading, mapping, drafting, testing, summarizing, and first-pass review.
The human should decide what matters.
Routing is necessary, but auto-routing is not authority
No single model wins every task.
That makes routing inevitable.
LLMRouterBench, a 2026 routing benchmark, evaluates more than 400,000 instances across 21 datasets and 33 models. It confirms strong model complementarity, but also finds that many routing methods perform similarly under unified evaluation and that several recent methods do not reliably beat simple baselines.
That matches the production reality.
Auto mode is useful for convenience.
It is not an authority for high-risk engineering.
A better routing policy has explicit lanes.
Cheap/default lane
Use for:
docs
formatting
summarization
boilerplate
simple scaffolding
low-risk edits
test naming
mechanical transformations
Standard frontier lane
Use for:
ordinary production implementation
debugging
feature work
test generation
codebase exploration
moderate refactors
Top-tier escalation lane
Use for:
failed loops
repeated test failures
ambiguous architecture
security-sensitive changes
schema/data migrations
release-critical code
adversarial review
Human-gated lane
Use for:
destructive operations
production changes
secrets
permissions
customer-impacting rollout
incident response
The labels matter less than the telemetry.
Track:
wrong-route corrections
repeated attempts
escalation rate
human intervention count
model switches
review latency
escaped defects
cost per accepted diff
That is how routing becomes engineering instead of vibes.
Proprietary context is both tax and asset
Every company has internal abstractions.
Some are strategic.
Many are accidental.
Models have strong priors for common public stacks. They have weaker priors for your internal framework, your release ritual, your service boundaries, your custom metadata model, your old migration convention, and the bug everyone “just knows” to avoid.
That creates a context tax.
The model needs more examples, more docs, more traces, more corrective feedback, and more human steering to do the same job.
The wrong answer is to dump everything into context.
The right answer is to separate proprietary surface into two buckets.
First: proprietary surface that is not differentiated
Reduce it.
Standardize it.
Wrap it.
Replace it.
Make it boring to the model.
Second: proprietary surface that is differentiated
Invest in it.
Make it machine-readable.
Create canonical examples.
Build runbooks.
Version skills.
Capture golden traces.
Add private evals.
Make the hidden system legible.
Anthropic’s Agent Skills documentation is a useful public example of this pattern: skills package instructions, metadata, workflows, and optional resources so Claude can load relevant domain-specific expertise on demand instead of repeatedly consuming the same context. The same documentation emphasizes progressive disclosure: metadata is always available, instructions load when triggered, and deeper resources are accessed only as needed.
Skills should not be treated as prompt snippets.
They are a mechanism for turning repeated human corrections into reusable workflow capital.
But skills can also become prompt debt.
So they need:
owners
versioning
triggering rules
evaluation
conflict detection
deprecation
telemetry
A good bug investigation should not end with a patch.
It should produce at least one durable artifact:
regression test
eval case
runbook
skill update
prompt/context rule
better dashboard
deleted abstraction
clearer API
improved release checklist
That is the compounding loop:
workflow → trace → evaluation → correction → skill → better workflow
If that loop belongs to the vendor, the company rents intelligence.
If that loop belongs to the company, the company compounds judgment.
Multi-agent work needs an operating system
The future is not one engineer chatting with one assistant.
It is many agents running in parallel:
one maps the codebase
one drafts a plan
one implements
one writes tests
one attacks the diff
one checks security
one prepares release notes
one watches post-release telemetry
one turns discoveries into reusable knowledge
Codex can work on tasks in the background, including in parallel, using its own cloud environment; it can also connect to GitHub repositories and create pull requests from its work.
That sounds powerful.
It is also how you create an expensive mess if the human becomes the scheduler.
Past a small number of concurrent streams, the bottleneck is not agent availability.
The bottleneck is state.
Which branch is blocked?
Which tests failed?
Which agent repeated work?
Which diff conflicts with another diff?
Which risk needs a human decision?
Which output is ready for serious review?
Which run should be stopped?
Which context is stale?
Which decision has already been made?
Multi-agent engineering needs a command center.
Not necessarily a fancy product.
But at least a shared state view:
task
branch
owner
agent role
model
prompt/context version
current plan
tests run
failures
blockers
risk level
cost so far
next required human decision
Without this, the senior engineer stops being an architect and becomes an interrupt router.
That is a bad trade.
The org chart changes, but not in the lazy way
The lazy story is junior replacement.
The better story is supervision capacity.
As code generation gets cheaper, verification gets more valuable.
The shape of engineering work changes.
Staff and principal engineers spend more time on:
architecture
decomposition
eval design
model steering
review standards
high-risk release decisions
Senior engineers spend more time on:
running agent pods
supervising parallel streams
owning service quality
converting ambiguous work into reviewable plans
Engineering managers and tech leads spend more time on:
review queues
bottleneck removal
ownership clarity
sequencing
cross-team coordination
making sure agent output does not overwhelm the human system
Junior and mid-level engineers should not be pushed out of the pipeline.
Their apprenticeship path changes toward:
verification
debugging
tests
observability
code reading
small scoped changes
agent operation
AI platform engineers become more important:
routing
evals
skill registries
context stores
telemetry
secure permissions
sandboxing
cost controls
SRE, QA, release, and security capacity also matter more, not less.
More generated code without more validation capacity is not productivity.
It is inventory.
Governance should control the work system, not just total tokens
A token cap is easy to understand.
It is also usually the wrong control surface.
Better metrics:
cost per accepted diff
cost per reviewed and shipped change
human interventions per PR
repeated attempts per task
model switches per task
wrong-route corrections
review latency
escaped defects
cache hit rate
duplicated agent work
percentage of agent tasks with evidence packages
percentage of incidents that improve runbooks/evals/skills
percentage of high-risk PRs with named human approval
percentage of agent-authored PRs with model/context version recorded
Also track the hidden cost:
re-reviewed diffs
conflicting branches
redundant context loading
repeated codebase reads
repeated explanations of the same internal abstraction
agent runs stopped because ownership was unclear
human attention lost to interruptions
That is where the waste hides.
The governance objective is not to minimize tokens.
The governance objective is to spend enough tokens to reduce avoidable human touchpoints while preserving human judgment at the places where judgment changes quality.
A narrow operating loop I would actually run
Start boring.
1. Set floors before caps
Do not plan below:
$100/user/month for any serious AI use case
$200/engineer/month for engineering use cases
The floor does not mean entitlement.
It means you are taking the workflow seriously enough to support real usage.
2. Every non-trivial agent task starts with a plan
The plan includes:
affected files/services
assumptions
open questions
risk areas
sequencing
test strategy
rollback concerns
Humans approve plans, not vibes.
3. Every agent output includes an evidence package
No evidence package, no review.
Minimum evidence:
plan
diff summary
tests run
failing tests
unresolved risks
security/performance notes
rollout notes
rollback notes
model and prompt/context version
4. Use adversarial review from a different model family for high-stakes work
Same-model self-review is better than nothing.
Cross-model review is better for correlated blind spots.
5. Put hard stops on repeated failure
No infinite retries.
Stop on:
repeated test failure
high-risk file paths
destructive operations
migration changes
missing tests
unclear ownership
unresolved ambiguity
6. Build a skill registry
Reusable procedures should become skills, not Slack lore.
But skills need owners, versioning, evals, and deconfliction.
7. Build private evals
Public benchmarks are useful.
They are not your production system.
Measure models on your real task classes:
migrations
debugging
release readiness
internal abstractions
security review
test repair
incident summaries
codebase navigation
PR evidence quality
8. Review budgets by outcome
Do not ask only:
who spent the most?
Ask:
what shipped?
how much human review did it consume?
how many attempts did it take?
what defects escaped?
what reusable knowledge was created?
what should be routed differently next time?
That is the difference between buying AI tools and building an AI-native engineering system.
The stable equilibrium
The model vendors will own a lot.
They will own more generic engineering intelligence than most companies expect.
They will make the average code review better.
They will make the average migration plan better.
They will make the average test-generation loop better.
They will make the average junior task cheaper.
They will absorb a lot of workflow scaffolding that companies currently think is special.
Good.
We should want that.
There is no moat in forcing humans to remember what a model can reliably surface.
But great companies will still own the harder thing:
context
authority
verification
accountability
taste
strategy
release risk
customer commitments
institutional memory
the learning loop around their own decisions
That is the equilibrium I trust.
More intelligence inside the model.
More authority outside the model.
Use the model as a cognitive engine.
Do not use it as the court of record.
Use model vendors aggressively.
Do not let them become your invisible control plane.
The future engineering function is not organized around who can type code fastest.
It is organized around who can define invariants, operate agents, verify outputs, own release risk, and turn failures into durable knowledge.
The model is not the moat.
The moat is the learning loop you can inspect, evaluate, govern, and carry across models.