

Is code still the source of truth?
Summary of my presentation at 2025 ELC Annual

I argued at ELC Annual that the center of gravity is drifting—from code to inputs about the code. Prompts, datasets, models, and evals are becoming the primary artifacts. That’s not a prediction; it’s merely connecting the dots backward and noticing what’s already changed.
The constraints we actually fight
Most of engineering is just pressure-testing three constraints: human cognition (complexity, coordination, bugs), provisioning at scale (deploy, redundancy, cost), and change risk (feedback loops). The tools that moved the needle before LLMs—managed runtimes, DVCS+CI/CD, containerization/cloud, observability—were all bets against those constraints.
What shifted with LLMs
Treating the model like a “compiler” works—until it doesn’t. Traditional compilers are deterministic; auto‑regressive models aren’t. Tiny prompt edits (or swaps between model families) yield materially different outcomes. That puts inputs—prompts, retrieval/context rules, tool schemas—and evaluation at the center. The inputs are the product.
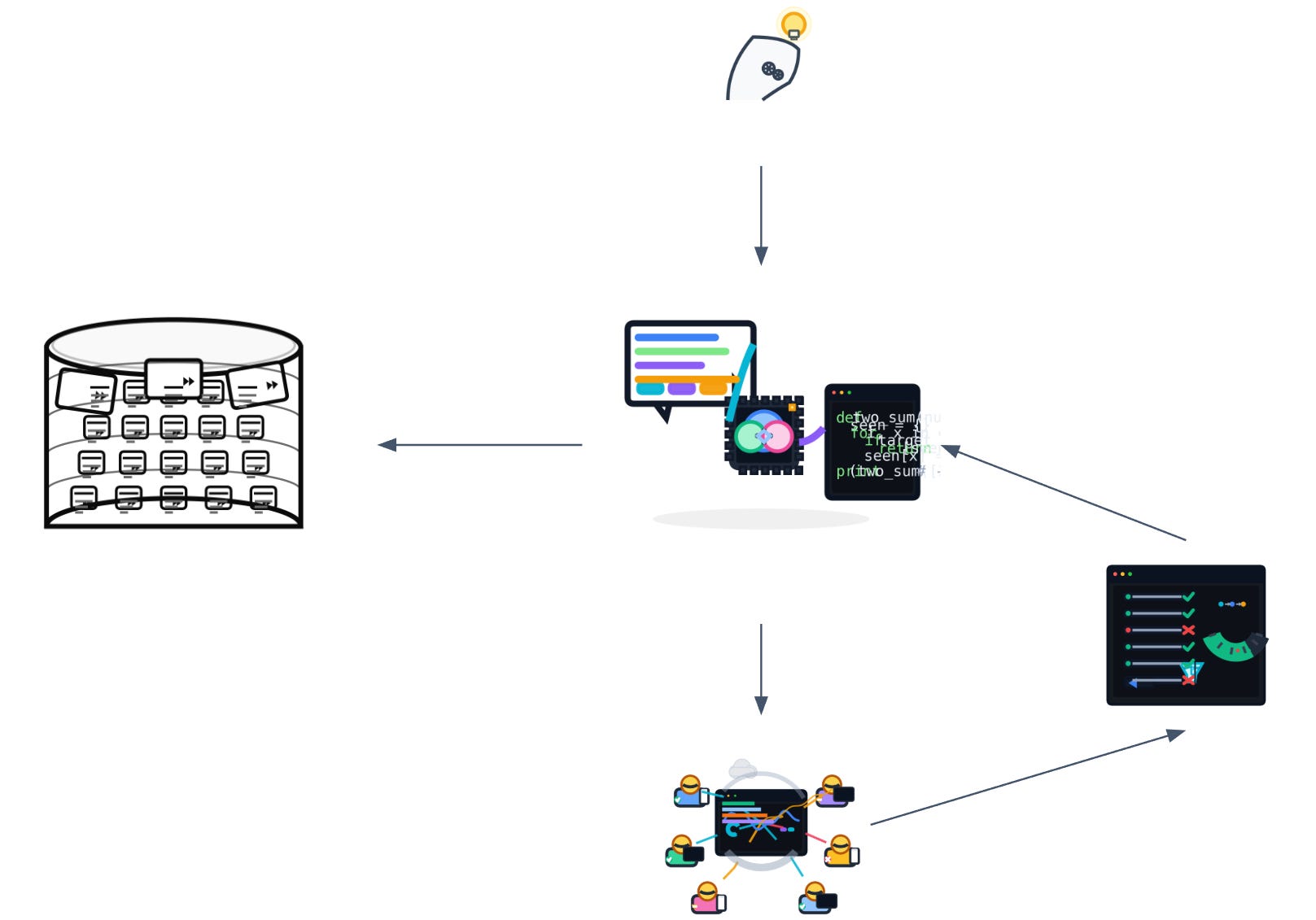
Two practical implications:
Inputs as first‑class artifacts.
Prompts (and flows), input datasets (docs, tickets, logs), models/fine‑tunes, and eval suites/user simulators all need real versioning, lineage, and regression checks—because models change under your feet.Evaluation is your safety rail.
You won’t guarantee determinism; you can bound behavior and catch drift. Invest in evals and forward simulation before you put agents anywhere near money or production.
Legacy, repos—and the new “rewrite”
“Full rewrite” used to be a dirty word. With LLM‑accelerated throughput, wholesale rewrites are increasingly viable when entropy makes understanding costlier than regeneration + hardening with evals.
What engineering is becoming
Zoom out and the job collapses into tooling and data.
Humans become what the models aren’t: (a) evaluators and (b) carriers of undocumented institutional knowledge. That’s where leverage lives.
Tech debt is dirty data.
Clean it, or it compounds.
A minimal operating checklist (until better tooling is available):
Check in prompts with code. Include tool schemas, context rules, guardrails, and tests.
Pin and record models. Track families/versions and fine‑tuning metadata like compiler flags. Expect drift.
Build evals before features. Scenarios, simulators, acceptance criteria—gate releases on them.
Prefer rewrite when entropy wins. If understanding cost > regeneration + eval hardening, start over.
Instrument everything. You can’t lead probabilistic systems blind.
None of this requires prophecy (Bohr and Feynman would approve); tempered by the reminder that auto‑regressive generation diverges without control.
The link to the full video
— Ruslan
Regarding the topic of the article, this is a very sharp observation. The shift to inputs as primary artifacts is spott on, even if it feels like we're just moving the complexity around, no?